AI recognizes anomalously deformed Kana
December 17, 2017
AI recognizes anomalously deformed Kana
Nam Tuan Ly in the 2nd year for M.Eng. and Kha Cong Nguyen in the 1st year for Ph.D. at the Tokyo University of Agriculture and Technology have won the best algorithm award in the PRMU algorithm contest in 2017 to read anomalously deformed Kana by computer, which was held by the Special Interest Group of Pattern Recognition and Media Understanding of The Institute of Electronics, Information and Communication Engineers (IEICE), Japan. Before this contest, they were also awarded the best paper award in November by 4th International Workshop on Historical Document Imaging and Processing (HIP 2017).
Awards Ceremony of the 21st Algorithm Contest on 2017/12/16 (SAT) by the Special Interest Group of Pattern Recognition and Media Understanding (PRMU) of The Institute of Electronics, Information and Communication Engineers (IEICE)
※ Published after Dec. 17, 2017
The evaluation results of level 2(*1) and 3(*2) are as follows:
- Level 2
- Accuracy on test data: 87.6% (1st / 23 teams)
- Processing time: 2.16 (sec/character) (10th / 23 teams) - Level 3
- Accuracy on test data: 39.1% (1st / 23 teams)
- Processing time: 0.43 (sec/character) (5th / 23 teams)
Review
The average scores evaluated by the committee of three reviewers on novelty, reliability and clarity are 4 of novelty, 5 of reliability and 4.33 of clarity (minimum score: 1 and maximum score: 5). The following points have been highly evaluated: no explicit segmentation; various configurations of the networks considered, multi-line detection and integration for level 3 and overall architectures.
Methods
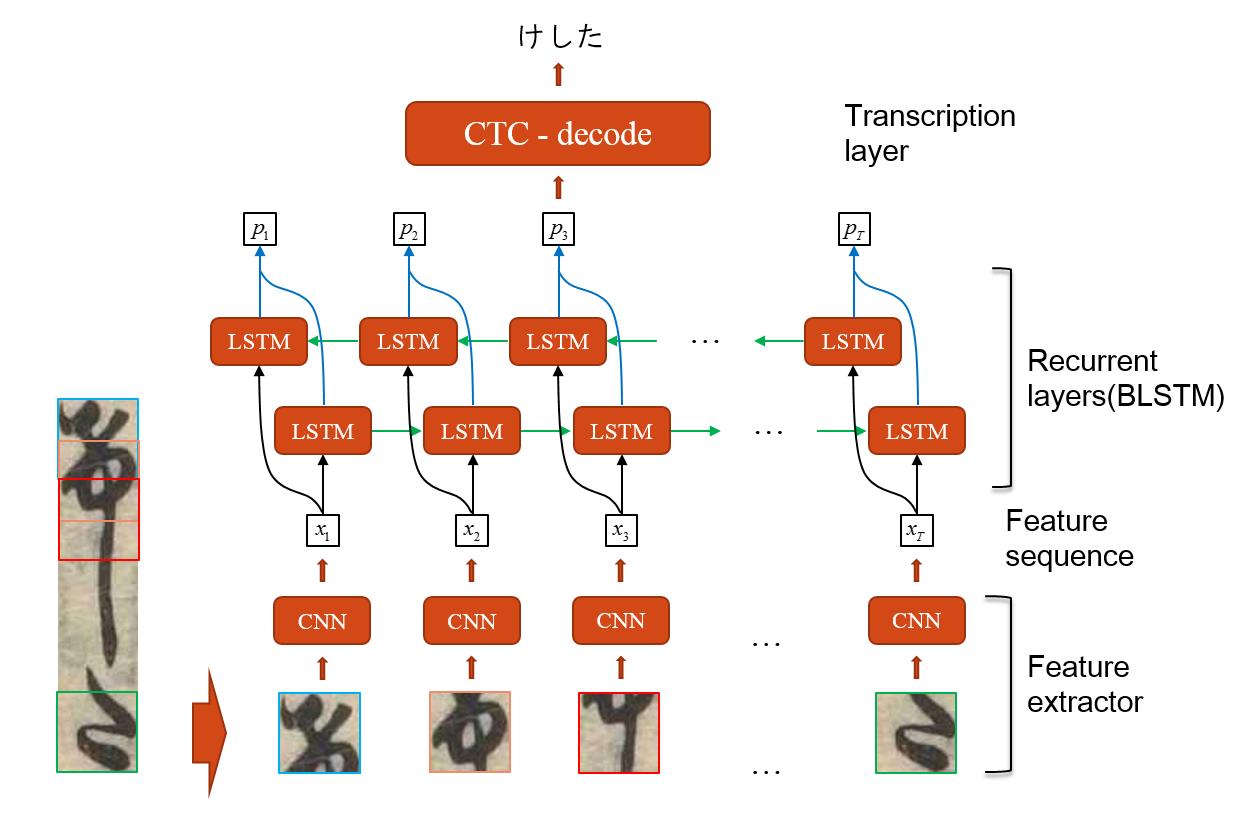
In the level 2, they employed a combined architecture of Convolutional Neural Network (CNN), Bidirectional Long Short-Term Memory (BLSTM), and Connectionist Temporal Classification (CTC). This architecture is named as Deep Convolutional Recurrent Network (DCRN). The architecture of DCRN consists of three components of a convolutional feature extractor, recurrent layers, and a transcription layer, from bottom to top as shown in Figure 1. From the bottom of the DCRN, the convolutional feature extractor extracts the sequence of features from an input vertical text line image by using the pretrained CNN, the recurrent layers employ the BLSTM to predict each frame of the feature sequence output by the convolutional feature extractor. At the top of the DCRN, the transcription layer translates the pre-frame predictions from the previous component into the final label sequence.
In the level 3, they first apply the vertical line segmentation by X-Y cut and Voronoi diagram methods. Then, they concatenate segmented lines into single vertical lines and utilize the method for level 2 to recognize them.
Future work
To archive old documents, transcribe them and avail them electronically is essential for historical and cultural researches. Many old documents are left without transcription, which imply the loss of history and culture. Since it is difficult for even experts, to recognized historical documents by computer is expected to contribute to the researches significantly.
At this moment, the recognition rate of level 3 of the method is still low. This is because misrecognition of a single character is counted as that of the entire sequence. Moreover, there are many confusing characters. In order to improve the accuracy, language models can be applied using language statistics at that time so that the accuracy of level 3 can be expected to approach to the accuracy of level 2. By accumulating more data, the recognition rate can be improved higher even for text including Kanji.
(*1) The overview of Algorithm Contest: PRMU of IEICE Japan has been holding the algorithm contest every year to encourage young researchers and students in this field and activate research activities. The theme of the contest is chosen from representative and fundamental topics. The proposed algorithms are evaluated from the viewpoints of accuracy (Detail: https://sites.google.com/view/alcon2017prmu).
(*2) The challenges and levels in the 21st Algorithm Contest:
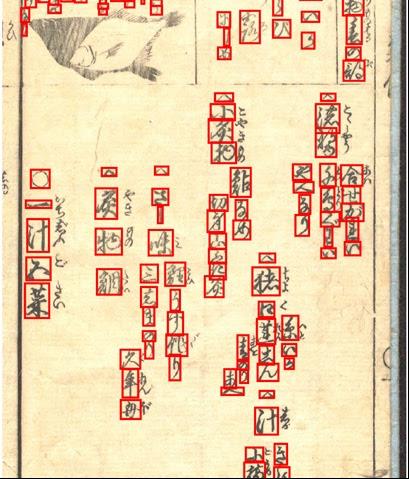
The anomalously deformed Kana in assigned area of historical documents as shown in Figure 2~4 must be recognized to the Unicode.
1. Task Difficulty
The tasks are divided into 3 levels according to the number of characters in a circumscribed rectangle, i.e., level 1: recognition of segmented single characters, level 2: recognition of sequences of vertically written three Kana characters and level 3: recognition of unrestricted sets of characters composed of three or more than three characters possibly in multiple lines.
2. Character to be recognized
About 50 categories of anomalously deformed Kana characters must be recognized (Kanji is not included).


◆Inquiries about this research◆
Masaki Nakagawa, Professor
Department of Computer and Information Sciences,
Tokyo University of Agriculture and Technology
e-mail: nakagawa(insert @ symbol here)cc.tuat.ac.jp
TEL/FAX: 042-388-7144